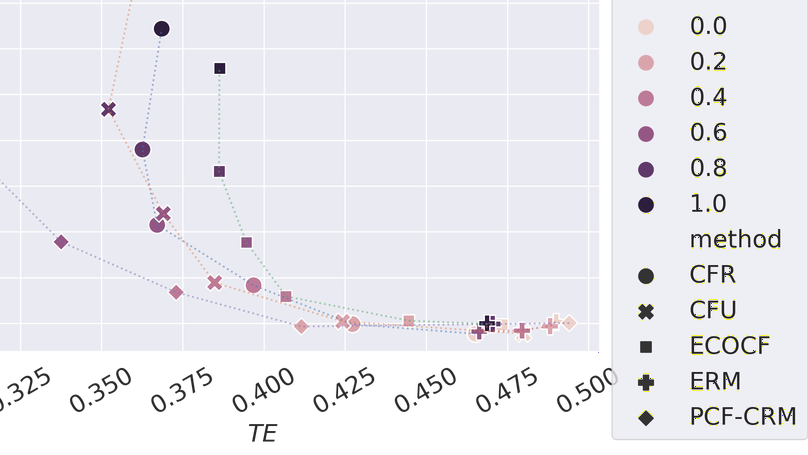
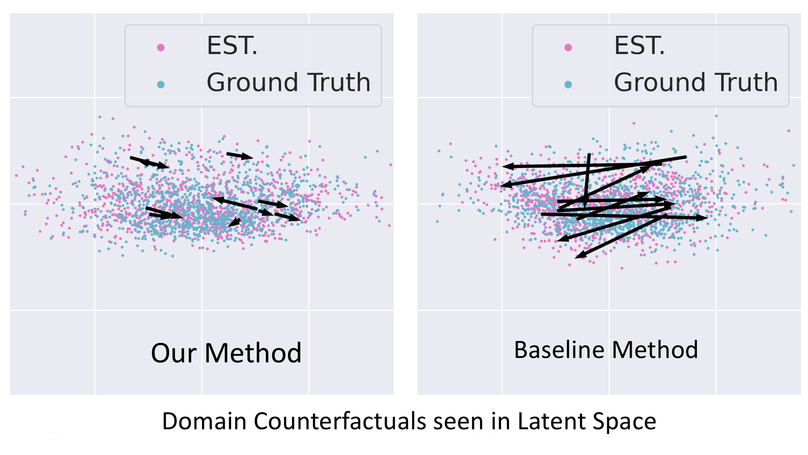
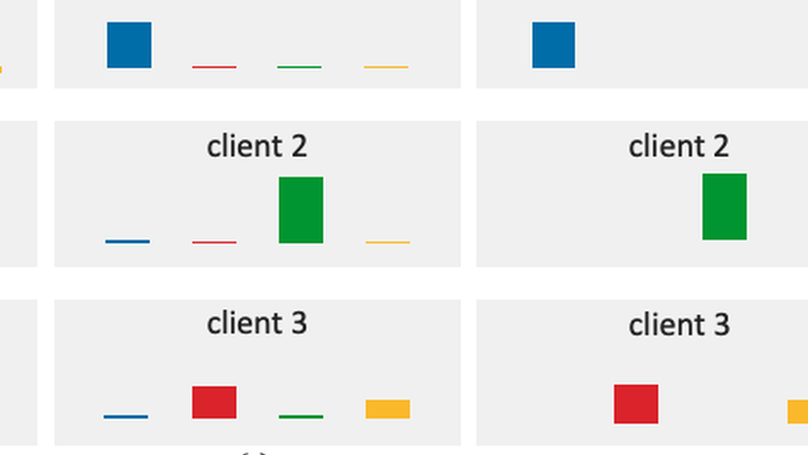
While prior federated learning (FL) methods mainly consider client heterogeneity, we focus on the Federated Domain Generalization (DG) task, which introduces train-test heterogeneity in the FL context. Existing evaluations in this field are limited in terms of the scale of the clients and dataset diversity. Thus, we propose a Federated DG benchmark that aim to test the limits of current methods with high client heterogeneity, large numbers of clients, and diverse datasets. Towards this objective, we introduce a novel data partition method that allows us to distribute any domain dataset among few or many clients while controlling client heterogeneity. We then introduce and apply our methodology to evaluate $13$ Federated DG methods, which include centralized DG methods adapted to the FL context, FL methods that handle client heterogeneity, and methods designed specifically for Federated DG on $7$ datasets. Our results suggest that, despite some progress, significant performance gaps remain in Federated DG, especially when evaluating with a large number of clients, high client heterogeneity, or more realistic datasets. Furthermore, our extendable benchmark code will be publicly released to aid in benchmarking future Federated DG approaches.